éncöding hèll (part 1)
If you ended up reading this, then you know what i am talking about. It's this garbled up text. That umlaut which got lost. Those diacritical marks that don't show up. And then first you blame the accent-grave-french, the umlaut-germans, the diacritic-czechs and so on (not even mentioning chinese/japanese/...languages) .
Why can't we all live with ASCII. Surely 8 bit ought to be enough for everyone;-)
So this is the first post on my encoding hell. I plan to follow up with more posts on this topic.

The situation
At Simplificator we recently worked on a ETL application. This application loads data from various sources (databases, files, services, e-mails), processes it (merge, filter, extract, enrich) and stores in various destinations (databases and files). This application is a central tool for data exchange between multiple companies. Data exchanged ranges from list of employees to warranty coverage of refrigerators. Not all sources are under our control and neither are the targets.
And this is where the problems started. Some sources are delivering UTF-8, some are using CP-1252, some are in ISO-8859-1 (a.k.a Latin-1). Some destinations are expecting ISO-8859-1 and some are expecting UTF-8.
ISO 8859-1 (ISO/IEC 8859-1) actually only specifies the printable characters, ISO-8859-1 defined by IANA (notice the dash) adds some control codes.
The problem
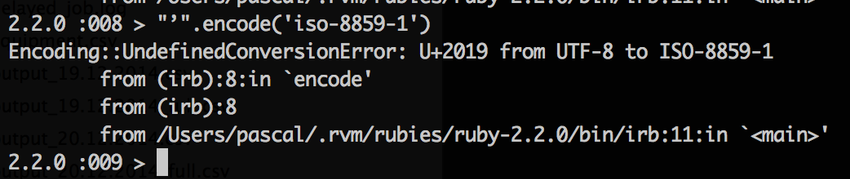
While in most programming languages it is easy to change the encoding of a string this sometimes includes more troubles than visible at first sight. Those encodings can contain from 256 to more than 1'000'000 code points. In other words: UTF-8 is a superset of CP-1252 and ISO 8859-1. Going from those 8 bit encodings to a (variable length) 4 byte encoding is always possible while for the other way it depends on the content. If an UTF-8 String contains characters which can not be encoded in 8 bit then you have a problem. Say hi to your new best friend the Encoding::UndefinedConversionError (or whatever your programming language of choice throws at you in such cases).
The solutions
There are two solutions for this. Both are relatively easy. And both might cause trouble by the consumers of your output. As mentioned the problem only shows when the content (or parts of it) are not covered by the destination encoding. CP-1252, ISO 8859-1 and UTF-8 share characters between 0020 and 007E (ASCII, without some control codes). As long as your content is within that range there is actually nothing to change when changing the encoding. But if your content lies outside this range then you either have to:
- Use UTF-8 for your output everywhere: Going from UTF-8/CP1252/ISO-8859-1 to UTF-8 is easy. As long as you stay in the current encoding or move from a "small" encoding to a "big" encoding you are safe. If possible, then this is the desirable solution.
- Use transliteration: This means mapping from one encoding to another. This can be achieved by replacing unknown characters with something similar or a special mark. So "Petr Čech" could become "Petr Cech" or "Petr ?ech". Depending on your use case one or another might be more appropriate.
The new problems
I told you... both solutions might cause troubles.
If the consumer of your output can not deal with UTF-8, then this is not an option. It would just move the problem out of your sight (which might be good enough ;-))
If you have changed the name of "Petr Čech" to "Petr Cech" and later on this data is imported again into another system, then it might or might not match up. I.e. If the other system is looking for user "Cech" but only knows about a user "Čech".
Also then transliteration (in our case) is irreversible. There is no way of going back to the original form.
Summary
If possible then stay within one encoding from input to processing to output. In my experience you’ll have fewer problems if you chose UTF-8 as it can cover a wide range of foreign languages, unlike ASCII, CP1252, ISO-8859-1.
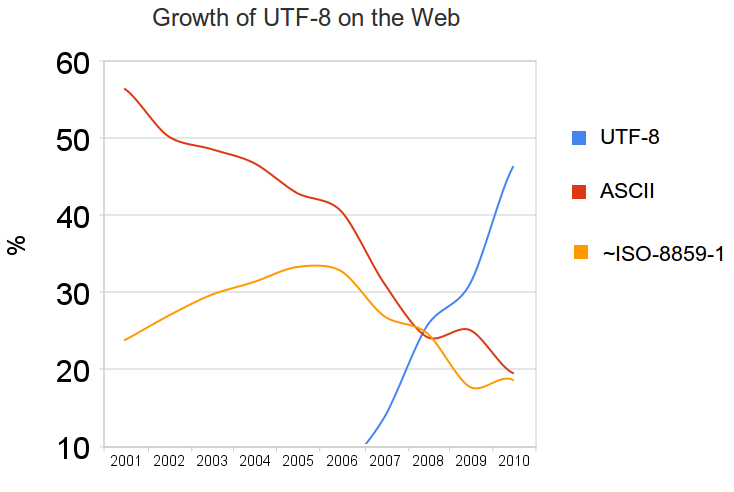
According to this Graph (source) UTF-8 is used more and more on the web. Hopefully one day we don't have to think about ISO-8859-1 anymore.